Introduction
Telethon Kids (Perth) is one of Australia’s largest medical research institutes with the vision to improve the health and well-being of children through excellence in research.
Telethon Kids conducts multiple research projects to find answers to some childhood diseases, conditions, and issues. Their research is focused on aboriginal health, brain and behavior, chronic and severe diseases, and early environment research.
Since 2018, Telethon Kids has been using OpenSpecimen for their ORIGIN project to track biospecimen collection and utilization.
ORIGINS Project
ORIGINS is a decade-long collaborative initiative between the Joondalup Health Campus (JHC) and the Telethon Kids Institute to establish a Western Australian (WA) birth cohort of 10,000 families enrolled during pregnancy.
“The project’s ultimate goal is to reduce the rising epidemic of non-communicable diseases through a healthy start to life.”
The project is five years into establishing a significant new birth cohort with detailed data and sample collection, including detailed environmental and biological profiling using cutting-edge technologies such as metagenomics, immune profiling, metabolomics, and genomics.
As a part of the ORIGINS study, the researchers follow pregnant mothers, their partners, and babies for the first five years of the baby’s life. The project collects detailed information on how a child’s early environment and parents’ physical health and genetics affect the risk of a wide range of diseases and conditions, e.g., asthma, eczema, food allergies, hay fever, diabetes, obesity, autism, etc.
ORIGINS is building a world-class biobank that will be helpful to researchers in studying the origin of non-communicable diseases and treatment options in children.
“Out of 10,000 participants, only 4,000 will have extensive follow-up and biospecimen collection. The remaining will have passive data collection. We are very close to reaching our extensive participant recruitments.” – Nina D’Vaz, the ORIGINS Biobank manager.
OpenSpecimen Implementation
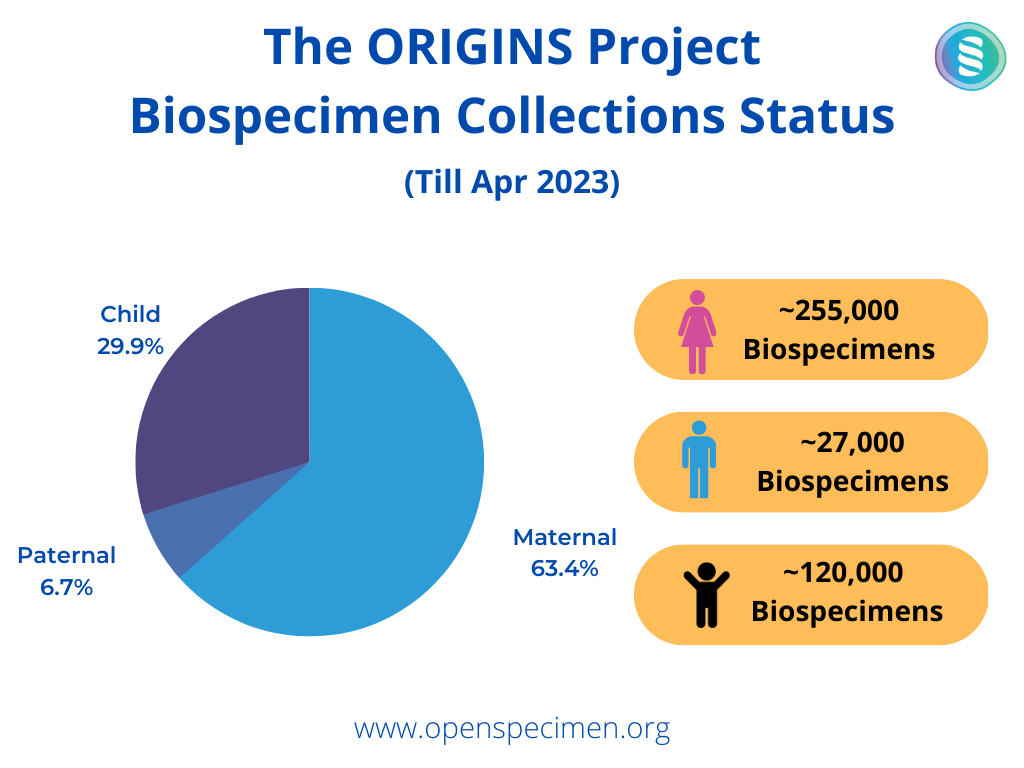
The ORIGINS biobank collects biospecimens under three main collection protocols: Maternal, Paternal, and Child. Simultaneously, multiple sub-studies are conducted to collect additional specimens and datasets. The participants can be part of more than one study if the criteria match.
The number of visits varies depending on the type of protocol and sub-studies under which the participants are enrolled. For example – the participant registered with the ‘Maternal Full Origin’ study and sub-study ‘Symba’ will show the Maternal study visits along with the ‘Symba’ sub-study visits.
As a part of the ORIGINS study, researchers collect specimens from all three types of participants (blood, urine, milk, etc.). In addition, some environmental specimens (e.g., house dust) are also collected.
Collecting biospecimens without quality data is of no use for research. During the recruitment of the women and their partners, a wide range of data is collected using various questionnaires, such as – details about their health, diet, physical activity patterns, and the factors in their environment.
“We collected data in Excel spreadsheets; some data was in REDCap. The data was accurate, but it was incredibly difficult to extract the data from it. Now that we have shifted to OpenSpecimen, we can pull any type of data easily.” – Nina D’Vaz, biobank manager, the ORIGINS Biobank.
OpenSpecimen-REDCap Integration
The below data is captured in REDCap during participant registration:
- Contact information
- Consents
- Survey questionnaires
- Longitudinal visits data
The longitudinal visits include but are not limited to 20 weeks, 28 weeks, 32 weeks, 40 weeks, or childbirth, 2-month visits.
The REDCAP data is automatically synced to OpenSpecimen using the REDCap integration plugin developed by Krishagni. This sync runs on a nightly basis. The REDCap project’s time points and data fields are mapped to Collection Protocol events in OpenSpecimen. The integration saves manual data entry time and eliminates human errors.
Biospecimen data management
Once participant and visit data is pulled into OpenSpecimen, the users log in to OpenSpecimen and collect biospecimen data for respective visits.
Earlier, it was tedious to collect biospecimen data since each participant had a varied number and types of specimens per visit.
The OpenSpecimen team configured specimen data collection pages to match their processing workflows. For easier storage, auto-allocation strategies are configured. It allows users to store specimens automatically in different boxes based on the type of visits and specimens in just one click. These configurations saved end-user data entry time, enhanced productivity, and reduced errors.
Reporting
The ORIGINS project aims to provide quality annotated biospecimens to researchers worldwide. Towards this, one of the key requirements for the Biobanking LIMS is the ability to generate reports easily based on requirements specified by the researchers.
Example reports:
- Cross-sectional reports, e.g., serum specimens at birth
- Longitudinal reports, e.g., how many participants have samples at all-time points
- Specimen collections over time (by month or year, etc.)
- Reports based on sub-studies
Using OpenSpecimen’s reporting module, end users can create queries across standard data fields, custom forms, and fields with complex expressions via the user interface without IT/SQL support.
Specimen Distribution
Currently, ~ 25 projects interact with the ORIGINS biobank. While some use only data, others use both specimens and data. The projects can be prospective or run as real-time projects, where they introduce interventions and collect biospecimens and data per their requirements.
The biobank collections are incomplete since not all kids have reached the last time point (5 years of age). The ORIGINS team plans to share the specimen catalog with more researchers once their collection is complete.